
Working Paper
The Narrow Depth and Breadth of Corporate Responsible AI Research
Nur Ahmed, Amit Das, Kirsten Martin, Kawshik Banerjee
Full paper: arxiv.org/abs/2405.12193
Media coverage: Nature Index, Nature News Feature
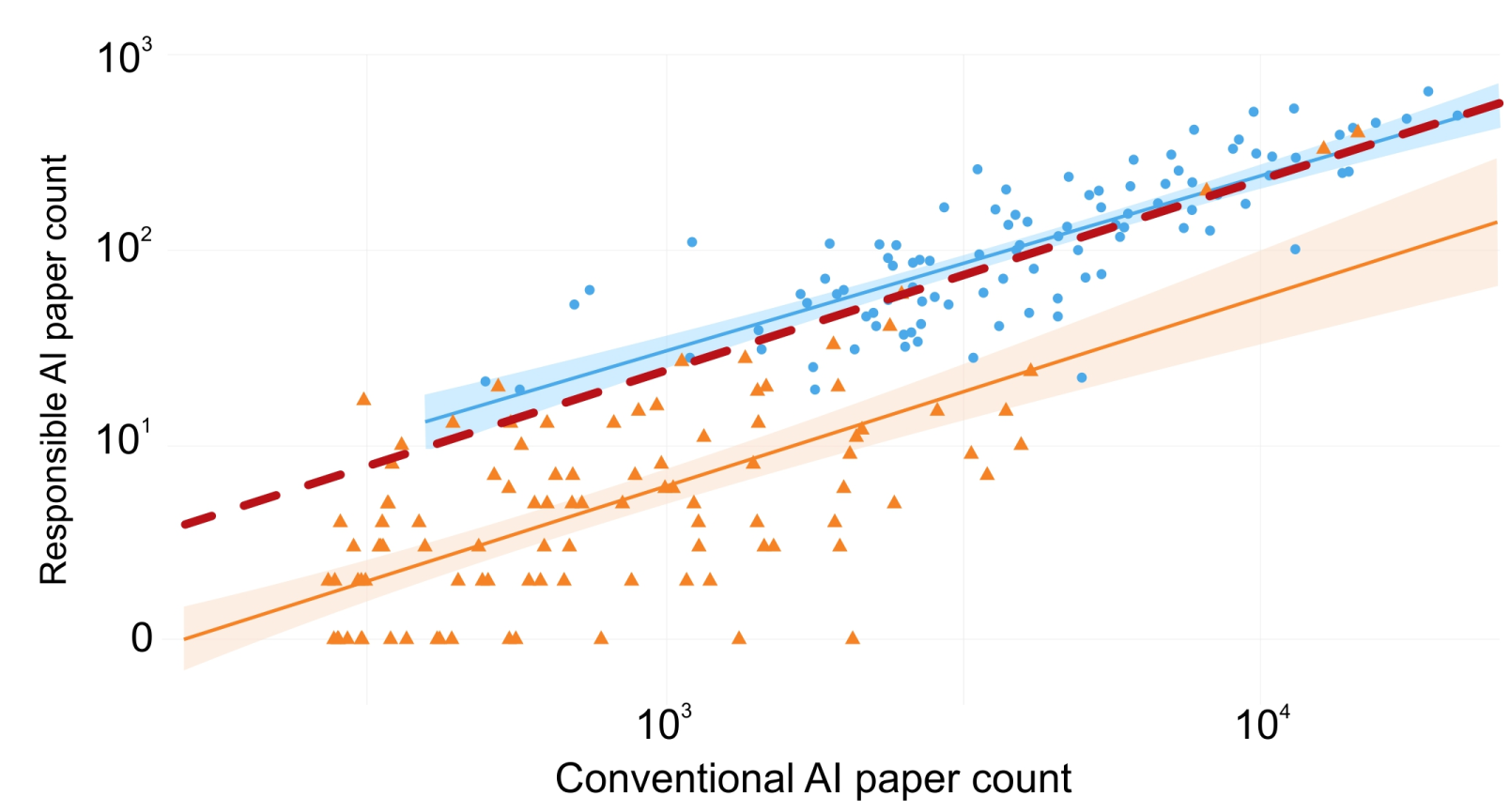
The transformative potential of AI offers both remarkable opportunities and significant risks, emphasizing the need for responsible AI development. Despite increasing focus in this area, understanding of industry engagement in responsible AI research remains limited. Our analysis of over 6 million peer-reviewed articles and 32 million patent citations reveals that most AI companies exhibit minimal engagement in responsible AI, contrasting sharply with their dominant presence in conventional AI research. Leading AI companies produce significantly less responsible AI research than their conventional counterparts or top academic institutions. Our linguistic analysis indicates a narrow focus in industry research, with limited topic diversity. Additionally, our patent citation analysis uncovers a disconnect between responsible AI research and AI commercialization, suggesting a lack of incorporation of academic research into the products they develop. This gap highlights the risk of AI development with potential unintended consequences due to insufficient ethical consideration. Our findings underscore the urgent need for industry to engage publicly in responsible AI research to foster trust and address AI-induced harms.
Conference Paper
Quantifying Shifts in Word Contexts from Social Media Data
Kawshik Banerjee, Md. Azmain Yakin Srizon, Md. Farukuzzaman Faruk, S.M. Mahedy Hasan, Md. Rakib Hossain
Accepted Venue: 2nd International Conference on Big Data, IoT and Machine Learning (BIM 2023)
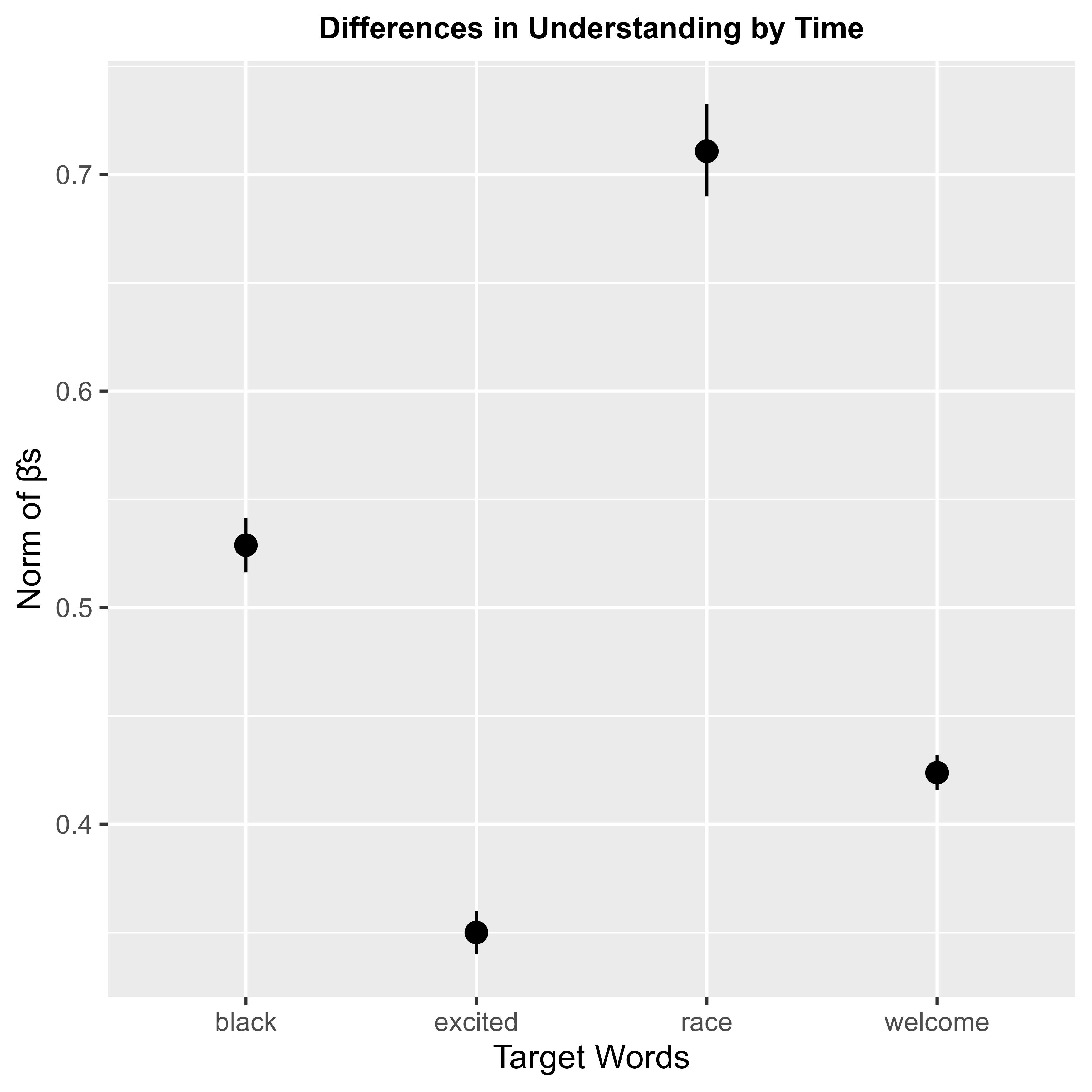
Words denote different things in different contexts. But measuring the differences and concluding whether such differences are statistically significant or not is a big computational challenge. Previous methods either needed larger datasets or were computationally intensive. But in this study, following a relatively simpler approach on a self-curated dataset of about 4 million tweets from top 300 US universities, such issues have been addressed. Using regression on embedded vectors of words, it is shown here that, after the mass protest defending the rights of the African-American people in the USA in 2018, there has been a statistically significant (p < 0.01) change in the usage of racial and ethnic stereotypical terms like "black" and "race," in comparison to trivial regular terms like "excited" and "welcome" in the social media. It is also shown how a word's association with other words can largely vary across time. Such methods can be used to address other problems in the field of computational linguistics in the future.